输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
5
/ \
2 6
/ \
1 3
示例 1:
输入: [1,6,3,2,5] 输出: false
示例 2:
输入: [1,3,2,6,5] 输出: true
提示:
数组长度 <= 1000
Related Topics
- 栈
- 树
- 二叉搜索树
- 递归
- 二叉树
- 单调栈
著书三年倦写字,如今翻书不识志,若知倦书悔前程 ,无如渔樵未识时
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
5
/ \
2 6
/ \
1 3
示例 1:
输入: [1,6,3,2,5] 输出: false
示例 2:
输入: [1,3,2,6,5] 输出: true
提示:
数组长度 <= 1000分段验证
分段验证
class Solution {
public boolean verifyPostorder(int[] postorder) {
return validate(postorder,0,postorder.length-1);
}
private boolean validate(int[] postorder, int left ,int right){
//如果左指针大于等于右指针了,说明当前节点以及没有子节点了,自然是符合条件的】
if (left>=right || left < 0 || right < 0) return true;
//找到这段数组对应的根节点,根据后序遍历的特性,即为这段数组的最后一位
int rootNum = postorder[right];
//初始赋值
int leftEnd = -1;
int rightStart = -1;
//开始遍历
for (int i = left; i < right; i++) {
if (postorder[i] < rootNum){
//如果这个值小于根节点的值,说明这个节点应该是在左子树中
leftEnd = i;
}
if (postorder[i] > rootNum && rightStart == -1){
//如果这个值大于根节点的值,说明这个节点应该是右子树上的
//且rightStart == -1 表示是第一次碰到的
rightStart = i;
}
}
//此时如果符合条件的话,应该是 leftEnd 在 rightStart 的左边一位
//或者 没有左子树:leftEnd == -1 且rightStart == left
//或者 没有右子树:rightStart == -1 且leftEnd == right-1
boolean validateResult = (leftEnd>-1 && rightStart> -1 && leftEnd+1== rightStart)
|| ( leftEnd == -1 && rightStart == left )
|| ( rightStart == -1 && leftEnd == right-1);
//自身验证完了,还要对分割好了的子序列的有效性判断
if (validateResult){
return validate( postorder, left, leftEnd ) && validate( postorder, rightStart, right-1 );
}
return false;
}
}给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
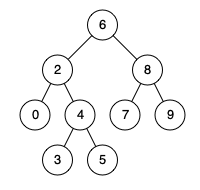
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 输出: 6 解释: 节点2和节点8的最近公共祖先是6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 输出: 2 解释: 节点2和节点4的最近公共祖先是2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
注意:本题与主站 235 题相同:https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-search-tree/
二叉搜索树特性
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (p.val > q.val){
return lowestCommonAncestor(root,q,p);
}
if (root.val == p.val || root.val == q.val){
return root;
}
if (root.val > p.val && root.val > q.val){
return lowestCommonAncestor(root.left,p,q);
}
if (root.val < p.val && root.val < q.val){
return lowestCommonAncestor(root.right,p,q);
}
return root;
}
}class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (p.val > q.val){
return lowestCommonAncestor(root,q,p);
}
TreeNode cur = root;
while ((cur.val > p.val && cur.val >q.val) || (cur.val < p.val && cur.val <q.val)){
if (cur.val > p.val && cur.val >q.val){
cur = cur.left;
}
if (cur.val < p.val && cur.val <q.val){
cur = cur.right;
}
}
return cur;
}
}比较简单,不做过多分析了
给定二叉搜索树(BST)的根节点 root 和一个整数值 val。
你需要在 BST 中找到节点值等于 val 的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 null 。
示例 1:

输入:root = [4,2,7,1,3], val = 2 输出:[2,1,3]
Example 2:

输入:root = [4,2,7,1,3], val = 5 输出:[]
提示:
[1, 5000] 范围内1 <= Node.val <= 107root 是二叉搜索树1 <= val <= 107根据二叉搜索树的左小右大的特性【递归&遍历树】
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
if (root == null){
return null;
}
if (root.val == val){
return root;
}
return root.val > val ? searchBST(root.left, val) : searchBST(root.right, val);
}
}应该没啥特殊的,二叉搜索树的特性
左子节点 < 根节点 < 右子节点所以照着这个写就行了
也可以改递归为遍历的写法,毕竟 递归和遍历循环是可以相互转化的
class Solution {
public TreeNode searchBST(TreeNode root, int val) {
while (root !=null){
if (root.val == val) return root;
root = root.val > val? root.left : root.right;
}
return root;
}
}给定一棵二叉搜索树,请找出其中第 k 大的节点的值。
示例 1:
输入: root = [3,1,4,null,2], k = 1 3 / \ 1 4 \ 2 输出: 4
示例 2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
输出: 4
限制:
中序遍历(倒着)
二叉搜索树、既然顺着中序遍历是连续递增的序列,先遍历右子树、然后跟节点、最后左子树这样的顺序来遍历的话,就是一个连续递减的序列了。
再找第K大的也就轻而易举了。
代码
class Solution {
int theK;
int theNum = -1;
public int kthLargest(TreeNode root, int k) {
theK = k;
dfs(root);
return theNum;
}
public void dfs(TreeNode node){
if (null == node){
return;
}
dfs(node.right);
if (theK==0){
return;
}
theK--;
if (theK==0){
theNum = node.val;
return;
}
dfs(node.left);
}
}将一个 二叉搜索树 就地转化为一个 已排序的双向循环链表 。
对于双向循环列表,你可以将左右孩子指针作为双向循环链表的前驱和后继指针,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
特别地,我们希望可以 就地 完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中最小元素的指针。
示例 1:

输入:root = [4,2,5,1,3] 输出:[1,2,3,4,5] 解释:下图显示了转化后的二叉搜索树,实线表示后继关系,虚线表示前驱关系。

示例 2:
输入:root = [2,1,3] 输出:[1,2,3]
示例 3:
输入:root = [] 输出:[] 解释:输入是空树,所以输出也是空链表。
示例 4:
输入:root = [1] 输出:[1]
提示:
-1000 <= Node.val <= 1000Node.left.val < Node.val < Node.right.valNode.val 的所有值都是独一无二的0 <= Number of Nodes <= 2000二叉搜索树+中序遍历 = 前驱后继关系对应的递增序列
一顿分析
根据题意,要求重新对应前驱后继关系的链表,那么自然想到的就是二叉搜索树的中序遍历操作。
那么我们就在中序遍历的过程中做文章
preNode,当前节点遍历结束的时候,把这个preNode指向到当前节点,这样到下一个节点的时候preNode指向的自然就是中序遍历的前一个节点,也就是当前节点的前驱节点preNode的right指向到当前节点,将当前节点的left指向到preNode,这样就算是完成了链表的基本链接操作tmpNode,将他的right指向到我们在中序遍历过程中遇到的第一个节点,这样head那边的指针关系也关联上了preNode自然就是中序遍历的最后一个节点了,而tmpNode的right又指向了第一个节点,所以我们再在这时候将两者关联起来代码
class Solution {
Node tmpNode = new Node();
Node preNode;
public Node treeToDoublyList(Node root) {
if (null == root){
return null;
}
dfs(root);
preNode.right = tmpNode.right;
tmpNode.right.left = preNode;
return tmpNode.right;
}
public void dfs(Node node){
if (null == node){
return;
}
dfs(node.left);
if (tmpNode.right == null){
//把虚拟头结点连接到最小节点
tmpNode.right = node;
}
if (preNode != null){
//连起来
preNode.right = node;
node.left = preNode;
}
preNode = node;
dfs(node.right);
}
}给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 个最小元素(从 1 开始计数)。
示例 1:

输入:root = [3,1,4,null,2], k = 1 输出:1
示例 2:

输入:root = [5,3,6,2,4,null,null,1], k = 3 输出:3
提示:
n 。1 <= k <= n <= 1040 <= Node.val <= 104
进阶:如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化算法?
【中序遍历 双解法】java中序遍历
简单没啥好特别的,搜索树的特性,左小右大,依次遍历的话是从最小的读起的那么对应数组的第k-1位就是所求
class Solution {
List<Integer> list;
public int kthSmallest(TreeNode root, int k) {
list = new ArrayList<>();
dfs(root);
return list.get(k-1);
}
public void dfs(TreeNode node){
if (node == null){
return;
}
dfs(node.left);
list.add(node.val);
dfs(node.right);
}
}如上代码,既然我们知道了由小到大的特性,那么其实就不用遍历整个二叉树了,只要按个遍历了k个节点,将第k个节点返回即可
class Solution {
int num = 0;
int k;
public int kthSmallest(TreeNode root, int k) {
this.k = k;
return dfs(root);
}
public int dfs(TreeNode node){
if (node == null){
return -1;
}
int left = dfs(node.left);
if (left >=0 ){
return left;
}
if (++num == k){
return node.val;
}
int right = dfs(node.right);
if (right >=0 ){
return right;
}
return -1;
}
}给定一个二叉搜索树 root 和一个目标结果 k,如果 BST 中存在两个元素且它们的和等于给定的目标结果,则返回 true。
示例 1:

输入: root = [5,3,6,2,4,null,7], k = 9 输出: true
示例 2:

输入: root = [5,3,6,2,4,null,7], k = 28 输出: false
示例 3:
输入: root = [2,1,3], k = 4 输出: true
示例 4:
输入: root = [2,1,3], k = 1 输出: false
示例 5:
输入: root = [2,1,3], k = 3 输出: true
提示:
[1, 104].-104 <= Node.val <= 104root 为二叉搜索树-105 <= k <= 105题解
继续还是二叉搜索树,牢记特性,左小右大,中序遍历后是一个有序递增数组。
那么直接一个中序遍历出来,这样题目就转换成在有个有序递增数组中寻找两个数的和能凑成k,是不是有点眼熟,对的,就是LeetCode刷题 【1】两数之和,先不管之前我们是怎么做的。
那么,按照目前最直观的思路,从数组结尾开始的两个数字尝试相加,假设对应索引为index1,index2,如果这两个位置的值相加比目标值k,大,则尝试将前面一个索引往前移动一位,找一个更小的值相加看是否等于k,一直找到索引为0的位置。如果这两个最大的值相加的合比k小,说明不存在相加了能满足k的情况了。尝试过一轮之后,如果找不到合适的值,则将后一位的索引往前移动一位,继续这个过程。
举例:【1,2,3,4,5,6,7,8】数组
先用7+8尝试,如果大于则用6+8、5+8、4+8尝试,直到1+7尝试,如果没有合适的,则进行下一轮用6+7尝试,5+7、4+7依次尝试。
好了,下面是代码:
class Solution1 {
List<Integer> list = new ArrayList<>();
public boolean findTarget(TreeNode root, int k) {
dfs(root);
int index1 = list.size()-1;
int index2 = index1-1;
while (index2>=0){
if (list.get(index1)+list.get(index2) < k){
return false;
}
while (index2 >= 0 && list.get(index1)+list.get(index2) >= k ){
if (list.get(index1)+list.get(index2) == k){
return true;
}
index2--;
}
index1--;
index2=index1-1;
}
return false;
}
private void dfs(TreeNode node){
if (null==node)return;
dfs(node.left);
list.add(node.val);
dfs(node.right);
}
}而执行的结果告诉了我,问题应该不至于这样
解答成功:
执行耗时:1138 ms,击败了5.24% 的Java用户
内存消耗:39.9 MB,击败了20.04% 的Java用户所以,回到上面的思路中间的过程看下,两个关键点“有序递增数组”,“在这个有序递增数组中寻找一个特定的值”,是不是很自然的就想到了此处应该可以用二分法来处理,此处后续省略。
重新再看下整个思考的过程,就是一个求解a+b=k的过程,其中k预先已给出,a、b值在对二叉树遍历的时候能知道一个,就是当前节点的值。此时问题就变成了再二叉树的所有节点中找另一个值是否存在。此时问题就转换成了,在二叉树遍历过程中,已知了a,已知了k,再在二叉搜索树中搜索(k-a)这个值是否存在,可利用二叉树的左小右大的特性查找。
代码:省略
接下来再进一步,在a+b=k的求解过程中,查找b能否进一步优化呢?答案是可以的,遍历每个节点的时候把值存储到一个hash表中,这样查找b是否存在就可以从原来的搜索二叉树查找转换成hash查找,时间复杂度直接降为O(1)。
class Solution {
HashSet<Integer> hashSet = new HashSet<>();
boolean result = false;
public boolean findTarget(TreeNode root, int k) {
dfs(root,k);
return result;
}
private void dfs(TreeNode node, int k){
if (null==node || result)return;
dfs(node.left,k);
if (!result){
if (hashSet.contains(k-node.val)){
result = true;
}
}
hashSet.add(node.val);
dfs(node.right,k);
}
}
结果
执行耗时:3 ms,击败了83.09% 的Java用户
内存消耗:39.2 MB,击败了79.23% 的Java用户再看看我们之前第一题是怎么做的,LeetCode刷题 【1】两数之和,是不是回到了一样的解法上了。
本题难度设定的是简单题,嗯,本质上就是在原来第一题两数之和的基础上嵌套了一个二叉树遍历。
另外做这题的时候想到的一个点,二叉平衡搜索树的查找搜索过程,和二分法数组查找搜索,这两个算法,本质上是一样的。